Database queries, functional style
NOTE: THE CODE IN THIS POST IS NOW OBSOLETE.
THE FOLD EXAMPLE IS IN THE DOCS NOW
Feel free to read for the design ideas though, these are still just as weird
Glowdust has come a long way since it was first designed, and by a long way I mean just enough for it to start making sense. The latest breakthrough was introducing types. I mostly treated them as syntactic sugar over functions and that worked out nicely, which is always a good sign. But it takes work to translate consistency to a useful feature, and success is not guaranteed.
Elegant doesn’t mean useful, is what I’m trying to say.
Until it does. And I think there is something interesting going on here.
Let me show you how to solve the problem of linked data traversal in a database with minimum fuss.
Self referential structures1
Let’s start with some type syntax, by defining a Glowdust type:
type Node {
id: int,
parent_id: int,
value: int,
}I am trying to create a tree stucture here, where Node objects are uniquely identified by id and have a parent
field that points to their parent node.
But wait, you will probably exclaim, Glowdust doesn’t support keys yet, does it?
No, it does not, and thank you for paying attention. But, the point of this post is to show that with just a bit of care, it doesn’t need to.
The previous declaration, in addition to the Node type itself, also creates a constructor function with signature
function Node(int, int, int) -> Node // not supported syntax yet, just for illustrationwhich basically takes values for the fields2 of the type and returns a struct.
I can now treat the id field as a key.
Practically, this means I can define a function Node(id: int) -> Node which returns the Node with that id, or ()
otherwise.
I can also use this function to store mappings from id to Node and persist things, like so:
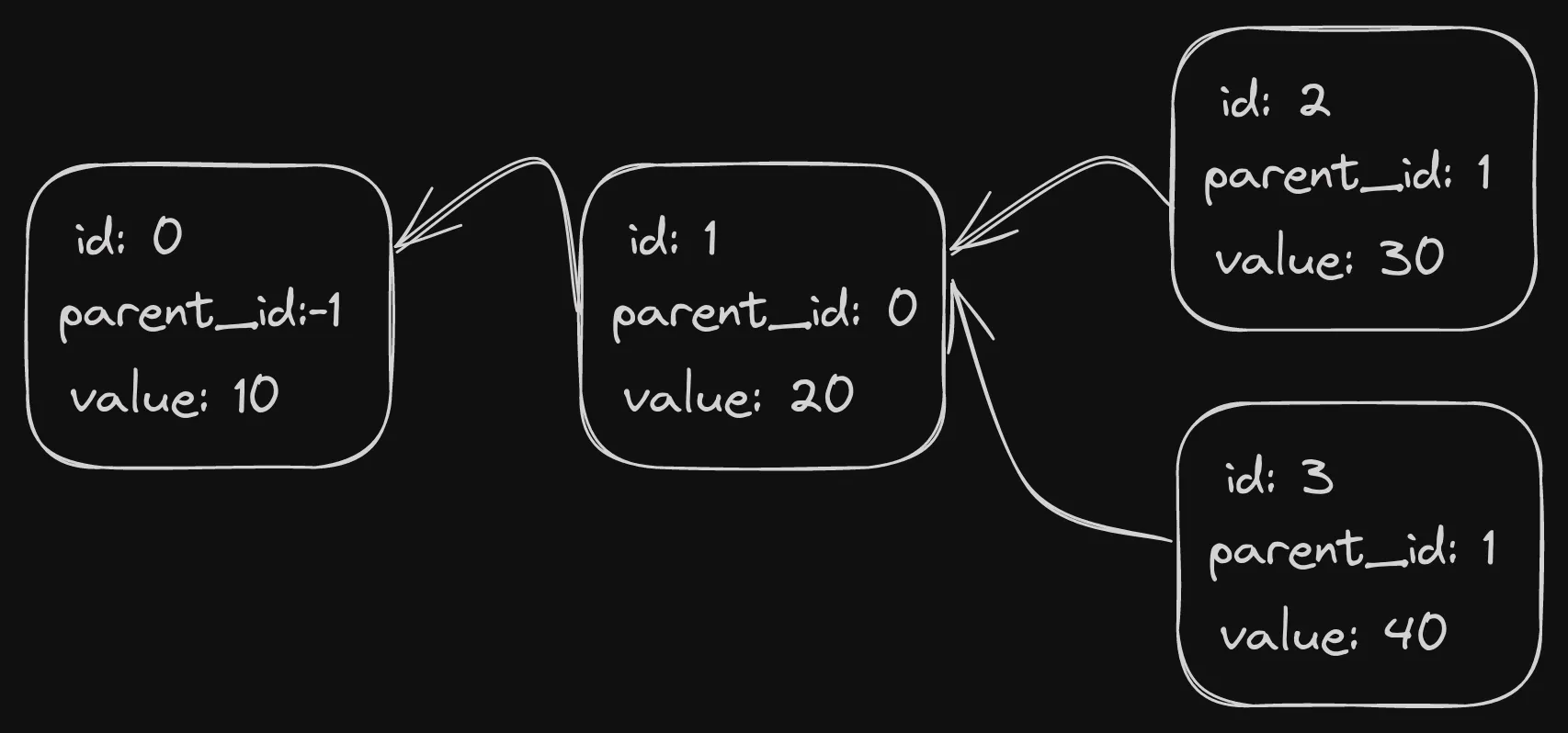
Node(0) = Node(0, -1, 10);
Node(1) = Node(1, 0, 20);
Node(2) = Node(2, 1, 30);
Node(3) = Node(3, 2, 40);There is nothing fancy about this function, it’s basic Glowdust, I just try to maintain the semantics of lookup-by-key
manually. As long as I lookup and store Node structs with the Node(int) function I just defined,
I will maintain key semantics and the parent pointers will work just fine.
The above 4 lines created a linked list of Nodes, looking like this:

If you’ve read the functions chapter of the Glowdust book
you’ll know that we can pattern match on parameters. Let’s use that to create a fold function over the nodes of our list:
function foldNode(-1, acc) = {acc}
function foldNode(id, acc) = {
node = Node(id);
foldNode(node.parent_id, acc+node.value)
}In short, if the id of the Node we’re folding over is -1, that means there is no parent Node and it terminates the recursion.
Otherwise, we recurse on the parent node and accumulate the sum of the values on the way.
We can use this function as is and fold over any Node, of course:
print(foldNode(2, 0))<<
60But much more interestingly, we can use this function in a query, like so:
match Node(id) -> node, return foldNode(id, 0)<<
[30]
[100]
[60]
[10]And we get the sum of values from each Node up to the root.
This query works even if we switch our list to a tree:
Node(3) = Node(3, 1, 40);Which makes our database look like:
match Node(id) -> node, return foldNode(id, 0) <<
[30]
[70]
[60]
[10]All of the above works today - you can run all of the code above in the Glowdust REPL - just follow the instructions to build it locally
Ok, so what?
But, you may think, there isn’t anything new here, this is just a programming language with extra steps. And yes, that’s kind of the point - to me, this is another demonstration that the functional model works unexpectedly well as a database model.
The fold example, even though it may seem trivial, solves in a very elegant way the problem of traversing recursive data structures in a database. Even graph databases have a problem with this, where they need to first find paths and then process them.
Upcoming features to make these examples more elegant
Here’s some ideas I’m experimenting with to make syntax above easier
I think it makes sense to annotate fields that are keys with, say, an asterisk. So the Node struct would look like
type Node {
*id: int,
parent_id: int,
value: int,
}Which would auto generate the Node(id: int) function. It would also make it trivial to have “pointer-lite” functionality, like so
type Node {
*id: int,
parent_id: *Node,
value: int,
}Because it is easy to derive that parent_id is an int field. The *Node is required because there are no nested structs allowed - this is a database after all.
Effectively, it forces the user to expect Node.parent_id to have type int.
Of course, there are little improvements for quality of life, like keeping in query scope variables defined outside of the match clause. These are more general improvements, but which will make filters and joins much easier to write.
So, do you find this interesting? Do functional patterns like the one described make your life easier when working with your database?
Give the above a spin and tell me if it works for you, or what you would change to make it more useful. The system is evolving and I can use all the input I can find.
As always, let me know your thoughts on Mastodon or by raising issues on the repo
And, if you find this interesting enough, you may want to donate towards the costs of developing Glowdust.
Footnotes
-
Disclaimer - I still don’t know what to call values of a custom type. Structures? Records? Facts, heavens forbid? I’ll stick with structures for now, but assume this is temporary. ↩
-
The parser supports named parameters for functions, but they are not currently used. You need to rely on the order of the arguents for now. ↩