Adding fallocate() to MinixFS
(skip the opening chit chat and go to the tech stuff)
Health warning
This post will probably make your eyes roll so much that you may hurt yourself. Read on at your own risk.
Why would anyone do this?
Asking “Why?” in the context of this blog is probably not the most productive question. It’s a “journey not the destination” kind of thing. But, it just so happens that this isn’t that weird of an exercise. Minix is a very simple filesystem, meant as a place for experimentation.
Why not ext4? Have you even looked at it? It’s insanely complex. The correct question would be “why on earth would you ever even look at ext4?”.
Besides, ext4 already supports fallocate, so there’s that too.
But, long story short, I am doing a thing and that thing requires zeroing out chunks of files. Now, fallocate with the FALLOC_FL_ZERO_RANGE flag will do just that. In ext4 however, it works by replacing the range with unwritten extents, which is insanely fast and requires almost no I/O. But I need those zeroes to be there and the I/O to happen.
Don’t ask.
In theory, I could modify the ext4 code to do that, but as stated earlier, it’s insanely complex and well beyond the scope of what I want to do. So I thought - hey, I could instead modify the fallocate implementation of a simple filesystem, like MinixFS.
Nope. MinixFS doesn’t support fallocate. I could do it by write()ing zeroes like a normal person, but then I would miss the opportunity to use my fancy new io-uring opcode. And in this blog’s universe, ZERO uring opcode is canon, there’s no way around not using them.
Besides, how hard can it be to add a new system call support to a filesystem?
Wow, just writing that last sentence gave me chills.
The answer is, it depends. If you know what you’re doing, it’s probably a lot of work, because you need things to function properly.
If, on the other hand, you are an unashamed hack that can barely navigate the kernel source tree, concerns like “correctness” are mere trifles. As long as it compiles, it’s good enough.
I am happy to inform you, in case you hadn’t noticed, that I am firmly of the latter persuasion. So, I’ll implement fallocate as a write() of zeroes.

As I said, an unashamed hack. Unrepentant even. But you’re already here, you’ve read this far, you might as well stick around a bit longer, see where this goes. I’ll try to make it worth it.
Adding the basic support
If you try to make an fallocate call on a Minix filesystem, you’ll get an Operation not supported error.
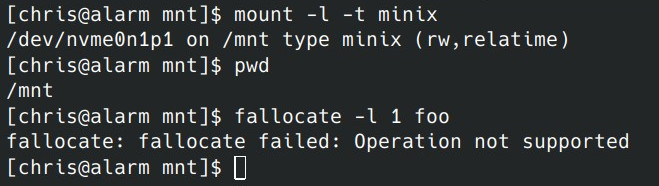
The man page lists the implementations that support the various flags and Minix is conspicuously absent. Let’s fix that. The unsupported part I mean, not the absent from man page part. I am a hack, but come on.
To get rid of this error, it is enough to add a no-op fallocate implementation to minix. Surprisingly, this takes only 5 lines of code, and here they are.
diff --git a/fs/minix/file.c b/fs/minix/file.c
index 906d192ab7f3..5e6c18d676c3 100644
--- a/fs/minix/file.c
+++ b/fs/minix/file.c
@@ -20,6 +20,7 @@ const struct file_operations minix_file_operations = {
.mmap = generic_file_mmap,
.fsync = generic_file_fsync,
.splice_read = filemap_splice_read,
+ .fallocate = minix_fallocate,
};
static int minix_setattr(struct mnt_idmap *idmap,
@@ -51,3 +52,7 @@ const struct inode_operations minix_file_inode_operations = {
.setattr = minix_setattr,
.getattr = minix_getattr,
};
+
+long minix_fallocate(struct file *file, int mode, loff_t offset, loff_t len) {
+ return 0;
+}
diff --git a/fs/minix/minix.h b/fs/minix/minix.h
index d493507c064f..8ff598e7ab96 100644
--- a/fs/minix/minix.h
+++ b/fs/minix/minix.h
@@ -55,6 +55,9 @@ extern int minix_getattr(struct mnt_idmap *, const struct path *,
struct kstat *, u32, unsigned int);
extern int minix_prepare_chunk(struct page *page, loff_t pos, unsigned len);
+
+extern long minix_fallocate(struct file *file, int mode, loff_t offset, loff_t len);
+
extern void V1_minix_truncate(struct inode *);
extern void V2_minix_truncate(struct inode *);
extern void minix_truncate(struct inode *);
The struct file_operations is the heart of the whole setup and part of the filesystem implementor’s API in the Linux kernel. Going into the details of how to implement a file system is beyond the scope of this article, but if you search for simple filesystem implementations you can find some good examples pretty easily.
If you build your kernel with this patch and run it, you will see that you can call fallocate on files on minix and no error comes back. Pretty cool.
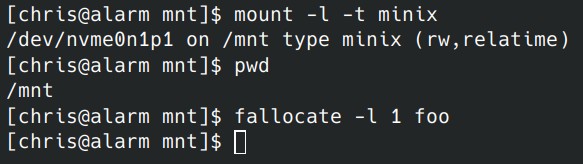
What’s not that cool is that nothing happens to those files. I’ll fix that next.
Sidebar: How to build and test the code in this post
You probably don’t want to be messing with your host OS to play around with these patches. That’s why I wrote up how to setup QEMU precisely for this purpose. It may not be the perfect setup, but it’s convenient, efficient and I even used it to do remote debugging of the kernel, so it’s pretty versatile.
Keep in mind that you will also need to enable built in support for Minix in your kernel build. Modules won’t work with this testing rig.
A dash of “implementation”
fallocate can do a lot of different things, depending on the mode it is asked to operate in. I will only look at the vanilla FALLOC_FL_ZERO_RANGE here and have the implementation return Operation not supported for everything else.
This means equality check on the mode argument, like so:
if (mode != FALLOC_FL_ZERO_RANGE) {
return -EOPNOTSUPP;
}
Then I will write the zeroes via a normal write call. This means allocate a buffer, fill it with zeroes and write it to the file.
The catch is that I don’t have a userspace buffer available in the method, which means I cannot call vfs_write, as that checks that the buffer address is in user space and fails if it’s not. Instead, I’ll use kernel_write.
void *buf = kmalloc(len, GFP_KERNEL);
if(!buf)
{
pr_alert("Failed to allocate memory");
return -ENOMEM;
}
memset(buf, 0, len);
int ret = kernel_write(file, buf, len, &offset);
kfree(buf);
return ret;
That’s it. That’s the whole function (full diff at the end).
And it works too, as per spec.
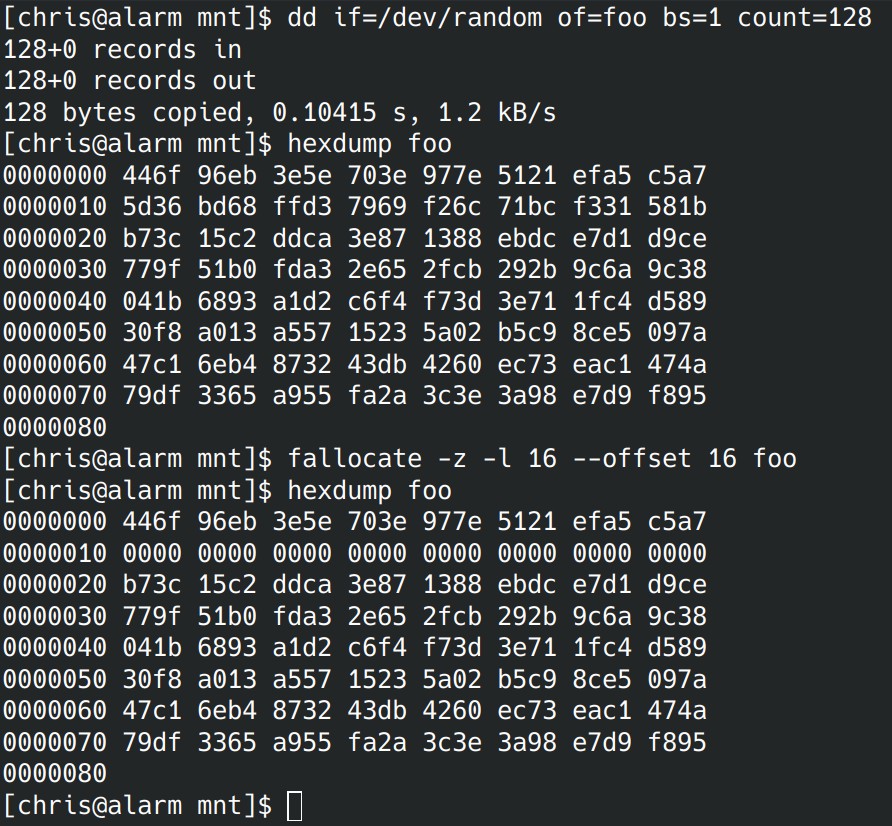
Now, to clarify. Implementing fallocate in terms of write defeats the reason fallocate exists in the first place. fallocate is meant to be an inode level operation, in order to manipulate large ranges within a file with minimal I/O. Ext4 can do it because it is extents based and can pseudo allocate unused blocks and read them back as zeroes without ever writing a single page on disk. Pretty efficient if you ask me.
But poor MinixFS has no such tricks up its sleeve. To do it properly, I would need to do much more extensive surgery on the minix codebase and that’s not what I’m after. Also, I actually want to zero the contents of the page cache for…a thing I want to do.
So, a fake implementation on top of write will work just fine.
A cliffhanger
As I mentioned, I hacked a new opcode in io_uring that does fallocate zero range. This should work on MinixFS too, right?
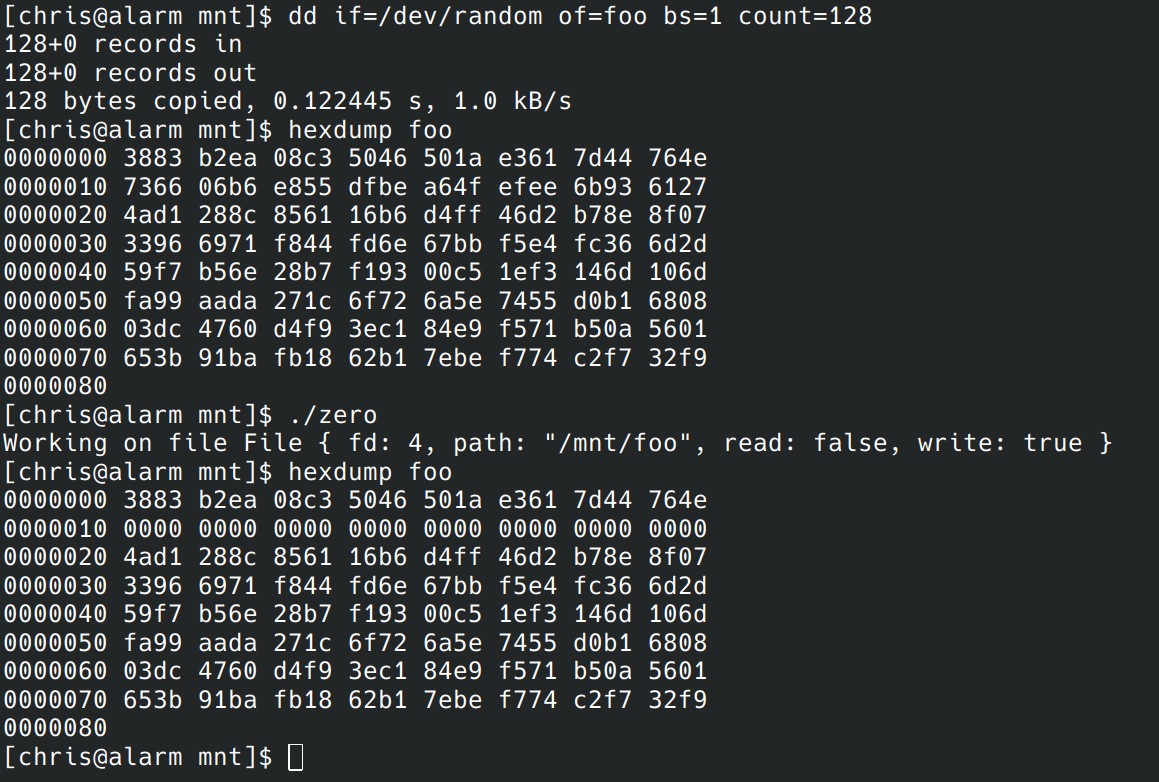
But this means I have a io-uring opcode called zero, that can zero out pages in the page cache in MinixFS. If only there was an NVMe command that would write out these pages as a single operation, perhaps called ZERO, that would be faster than an NVMe WRITE.
That would make a very nice, concise I/O stack roundtrip for zeroing out disk contents, by introducing a new “fake” NVMe command.
How nice would that be. Oh well, who knows, maybe someday someone will write a post like that.
If you follow me on Mastodon, I’ll let you know if I come across anything like that.
The code
Minix fallocate implementation
diff --git a/fs/minix/file.c b/fs/minix/file.c
index 906d192ab7f3..6f166a440e06 100644
--- a/fs/minix/file.c
+++ b/fs/minix/file.c
@@ -8,6 +8,7 @@
*/
#include "minix.h"
+#include <linux/falloc.h>
/*
* We have mostly NULLs here: the current defaults are OK for
@@ -20,6 +21,7 @@ const struct file_operations minix_file_operations = {
.mmap = generic_file_mmap,
.fsync = generic_file_fsync,
.splice_read = filemap_splice_read,
+ .fallocate = minix_fallocate,
};
static int minix_setattr(struct mnt_idmap *idmap,
@@ -51,3 +53,22 @@ const struct inode_operations minix_file_inode_operations = {
.setattr = minix_setattr,
.getattr = minix_getattr,
};
+
+long minix_fallocate(struct file *file, int mode, loff_t offset, loff_t len)
+{
+ if (mode != FALLOC_FL_ZERO_RANGE) {
+ return -EOPNOTSUPP;
+ }
+
+ void *buf = kmalloc(len, GFP_KERNEL);
+ if(!buf)
+ {
+ pr_alert("Failed to allocate memory");
+ return -ENOMEM;
+ }
+
+ memset(buf, 0, len);
+ int ret = kernel_write(file, buf, len, &offset);
+ kfree(buf);
+ return ret;
+}
diff --git a/fs/minix/minix.h b/fs/minix/minix.h
index d493507c064f..1a7906db88ff 100644
--- a/fs/minix/minix.h
+++ b/fs/minix/minix.h
@@ -64,6 +64,8 @@ extern int V2_minix_get_block(struct inode *, long, struct buffer_head *, int);
extern unsigned V1_minix_blocks(loff_t, struct super_block *);
extern unsigned V2_minix_blocks(loff_t, struct super_block *);
+long minix_fallocate(struct file *file, int mode, loff_t offset, loff_t len);
+
extern struct minix_dir_entry *minix_find_entry(struct dentry*, struct page**);
extern int minix_add_link(struct dentry*, struct inode*);
extern int minix_delete_entry(struct minix_dir_entry*, struct page*);
io-uring driver
use io_uring::{opcode, types, IoUring};
use std::os::unix::io::AsRawFd;
use std::io;
use std::fs::OpenOptions;
use std::io::Error;
fn main() -> io::Result<()> {
let mut ring = IoUring::new(1)?;
let fd = OpenOptions::new().write(true).open("foo")?;
println!("Working on file {:?}", fd);
let zero_e = opcode::Zero::new(types::Fd(fd.as_raw_fd()), 16 as _)
.offset(16)
.build()
.user_data(0x42);
unsafe {
ring.submission()
.push(&zero_e)
.expect("submission queue is full");
}
ring.submit_and_wait(1)?;
let cqe = ring.completion().next().expect("completion queue is empty");
assert_eq!(cqe.user_data(), 0x42);
assert!(cqe.result() >= 0, "zero error: {}", Error::from_raw_os_error(-cqe.result()));
Ok(())
}