Glowdust's first peristent store
Design goals
At this stage of its development, glowdust has…unusual requirements for its storage - requirements that are completely different than what you’d expect from a proper, adult DBMS.
For example: Efficiency.
A production DBMS needs to make efficient use of storage.
Ok, fine. Efficient-ish.
Glowdust, currently, doesn’t care about efficiency. I can waste all the space, because the amounts of data I persist are minuscule. Most of it comes from the integration tests that store a few records and then delete everything. Who cares that it takes 2 kilobytes when it could have taken 500 bytes? 4 times the disk footprint matters only when you have a lot of data.

Do you know what actually matters? The ability to debug.
That’s it, really. That’s the number one concern: being able to see what the system does.
If I ask it to store an integer, it must be as easy as possible to see that indeed it stored an integer, at the correct place. Everything that stands between me and the contents of the store is a hurdle for debugging and wastes development time.
“But Chris”,
you may ask
“why waste time developing something you’ll throw away anyway?”
Excellent question. A few reasons, actually.
One is, I don’t yet have a good architecture plan for storage. The reason for that is that an efficient database file format is developed together with everything else. You see, database management systems are
…gasp…
systems. They are developed as a whole and their pieces need to work together. I barely have any of the pieces right now, and definitely nothing for storage. The delta between <no store> and <any store> is immeasurably larger than the delta between <any store> and <good store>.
Another reason is that currently the goal for glowdust is to get just enough functionality to flesh out the data model. Good storage makes no sense when I haven’t even written a query parser yet.
Now, the obvious question is - what is the most debuggable data format?
Correct. It’s text. Well done. And how do you store values and types and stuff in text?
That’s right. JSON.
Wait. Hold on a bit. Values and Types?
Oh right. Yeah. I should probably talk about this.
This is a simple Glowdust program that creates a function named “book” with one definition and one value
define book(a) = {a} // <- define a function named book that returns its argument by default
book(-42, "forty-two", false, Nil) = (1, false, "") // <- except for this valueKind of a weird definition, but this is for demonstration purposes.
Glowdust has types for its literals and will have strong types for its variables and arguments. In fact, I think a
strong type system, similar to what Rust offers, will be necessary. But for now, there are String, Integer,
Boolean and Nil1. No user defined types yet. 2
Currently, the base type is enum Primitive:
#derive(Eq, PartialEq, Clone, Debug)
pub enum Primitive {
Nil,
Boolean(bool),
Integer(i32),
MyString(String),
}From that, I built up a hierarchy of Value and Object types that are probably too verbose and confusing,
but will do for the time being. I’ll simplify these soon, but for now be patient with the spaghetti types in the
JSON below. It’s ugly, but it works.
Here’s what the book definition from above looks like when serialized to JSON.
FunctionObject { // root
name: "book", // function name
definitions: [ // array of definitions
FunctionDefinitionObject { // a definition
formal_arguments: [ // the formal arguments for the definition
Variable(Variable { // A variable
index: 0, name: "a", initialized: false // the variable name and some info
})
],
constants: [], // no constants from the function body
variables: [], // no variables from the function body
arity: 1, // number of arguments
bytecode: [20, 0, 18], // the actual bytecodes of the body
bytecode_lines: [2, 2, 2] }], // debug information
values: { // the set of value mappings
TupleObject { // a TupleObject that makes up the key
arity: 4, // arity of the tuple
members: [
PrimitiveValue(Integer(-42)), // an integer, -42
PrimitiveValue(MyString("forty-two")), // a string, "forty-two"
PrimitiveValue(Boolean(false)), // a boolean, false
PrimitiveValue(Nil) // nil
]
}:
ObjectValue( // the value of the mapping
Object { // is an object
o_type: Tuple( // a tuple object, specifically
TupleObject {
arity: 3, // with 3 members
members: [
PrimitiveValue(Integer(1)), // an integer, 1
PrimitiveValue(Boolean(false)), // a boolean, false
PrimitiveValue(MyString("")) // and a string , ""
] }),
hash: 1 })} } // hash that I don't compute properly yetThis serialization/deserialization is done with serde.rs. I won’t write about this more, conceptually
it’s really simple, an isolated mechanic of “take an object and make it into JSON”. That’s all there is to it.
Just code.
Write a string to a file, they said. It will be simple, they said.
And they were right, whoever they are. There really isn’t much to writing a string to a file.
Except.
To deserialize a definition from a JSON string to a Rust struct, I need to read the correct string - no more and no less characters. That’s not hard to deal with.
On serialization, I just call len() on the string and write that value before I write the string, as a byte
(a byte suffices for now, I can easily increase this later).
On deserialization, I read a byte first, so I know the length, then I create a u8 buffer with that size and
read that many bytes into it. Then, I make that into a string and pass to serde.rs to deserialize. Easy.
Except.
What about modifications? Say I add some bytecode to a definition. If the strings are one right after the other in the file, then changing the length of one of them in the middle means I need to shift everything downstream forwards or backwards to make space or fill the gap. That sounds like too much work.
And it is.
A lot, and I mean a lot of techniques have been developed to deal with this problem. Thankfully, a very simple one is to just use fixed size records.
You design your file as a sequence of records with a fixed size and everything you do needs to fit in that size. If it doesn’t, you just reject it.
Blunt? Yes.
Simple? Absolutely. Also, quite fast.
Ok, fine. I guess you can have pointers chaining multiple records together, in a singly or doubly linked list or other fancy structures. But why do that when I can not do that?
I opted for a 1024 byte record size. The definition must fit in it or it’s rejected.

Since I already have a byte at the start of the record with the length of the string, I can still deserialize easily and then move the read/write offset to the next integer multiple of the record size to read or write the next entry.
The span of the record between the last byte of the definition and the end of the record is filled with zeroes.
But check this out.
With fixed size records, I can do updates in place, by overwriting the old entry. Create the new record, seek the file to the correct offset, write the buffer. Update done.
You want to delete a definition? Add a new byte at the start of the record, and use a bit to mark the record as deleted. Skip marked records when scanning the file, and reuse them to write new definitions.
Have I implemented any of that? Not yet. Both updates and deletes currently happen in memory and end up rewriting the whole file, truncating what’s left, if the new definition list is smaller.
Anyway.
All this goes into a file with a filename that is made from the function’s name and a .def extension. Presence of
this file means the function with this name has been defined. I could, in theory, store all function definitions in
a single file and search through them. Instead, by relying on the filename to lookup functions, I practically
outsource name indexing to the filesystem. It also means I can very easily see which functions are defined by
using ls. I can also cat a file to get the contents of a specific function - super convenient.
What’s missing from the .def file is the values array. These I serialize separately, in their own file,
described below.
In the end, here’s what the .def file format looks like:

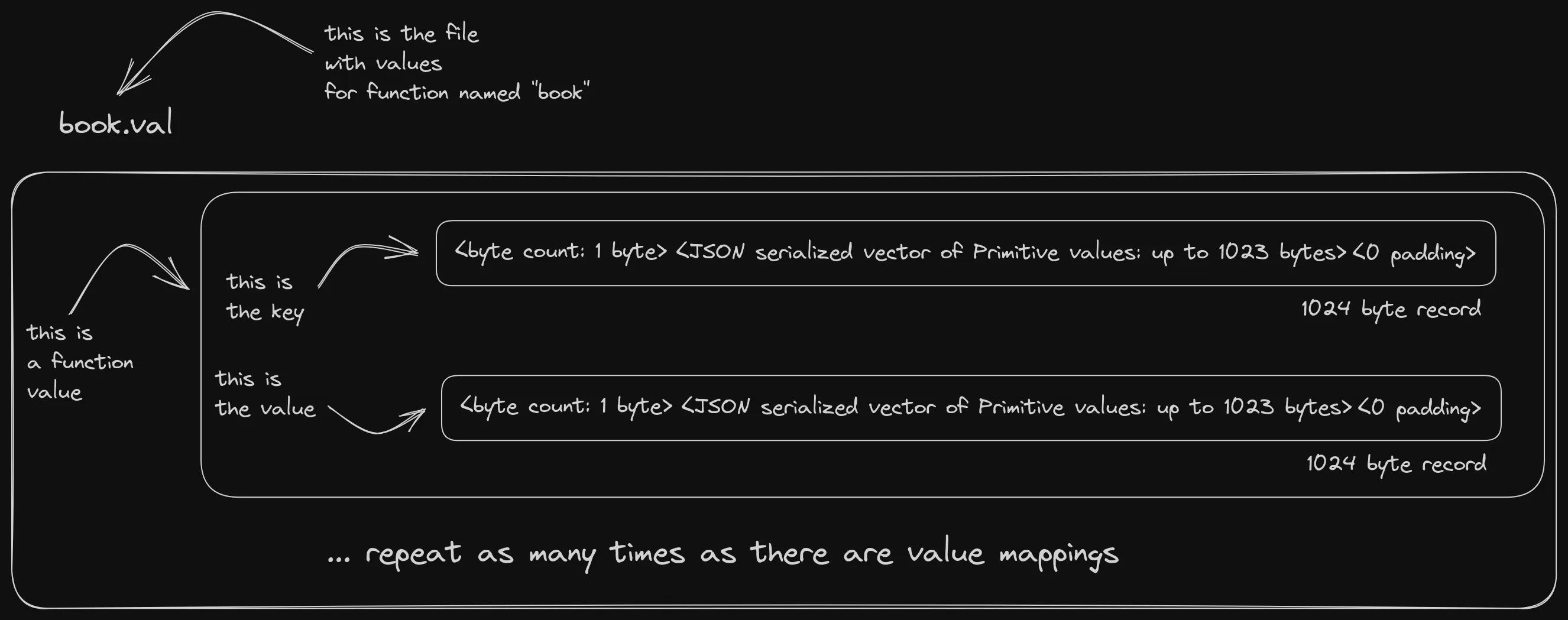
Values
Values follow the same design. 1024 byte records, first byte is the length and record is zero padded. Each key/value pair is serialized in two consecutive records, first the key, then the value.
Why split the values to a different file? Two reasons.
One is, values are simple and numerous - they form the bulk of the data and have a straightforward structure.
Once they work, debugging them should be rare and I don’t want to have them clutter the contents of the more
complex and error prone .def file.
The other is that serde cannot serialize Maps with non string keys and I couldn’t be bothered to implement a workaround.
Finally, the filename is made up of the function name, but with a .val extension.
The structure of the value store looks like this:
Future work
And when I say future, I mean right after I publish this post.
For the store, I think the best candidate is adding a flags byte at the start of the record, so I can mark records in use/not in use. To use that, I’ll need to be able to delete values and definitions, which is not currently a thing Glowdust does, so I’ll need to add delete/alter commands.
Then I think a REPL will come in handy, for quick interactive checks - you know, modify a function, dump the store to see what happened, rinse, repeat. Saves me the trouble of writing tests and modifying source code for simple things.
But these are just distractions from the big item that is ahead of me - getting some queries working.
If you want to follow along with the development, I have gotten into the habit of doing development livethreads in Mastodon. You can find me at https://fosstodon.org/deck/@chrisg - there you can also ask questions or make comments about this post.
Thank you for reading this far.